用Java来测试Avro数据格式在Kafka的传输,及测试Avro Schema的兼容性
2021-04-12 09:28
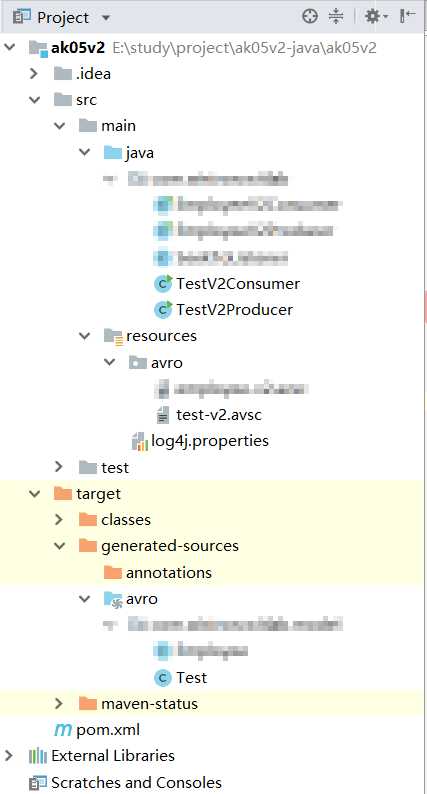
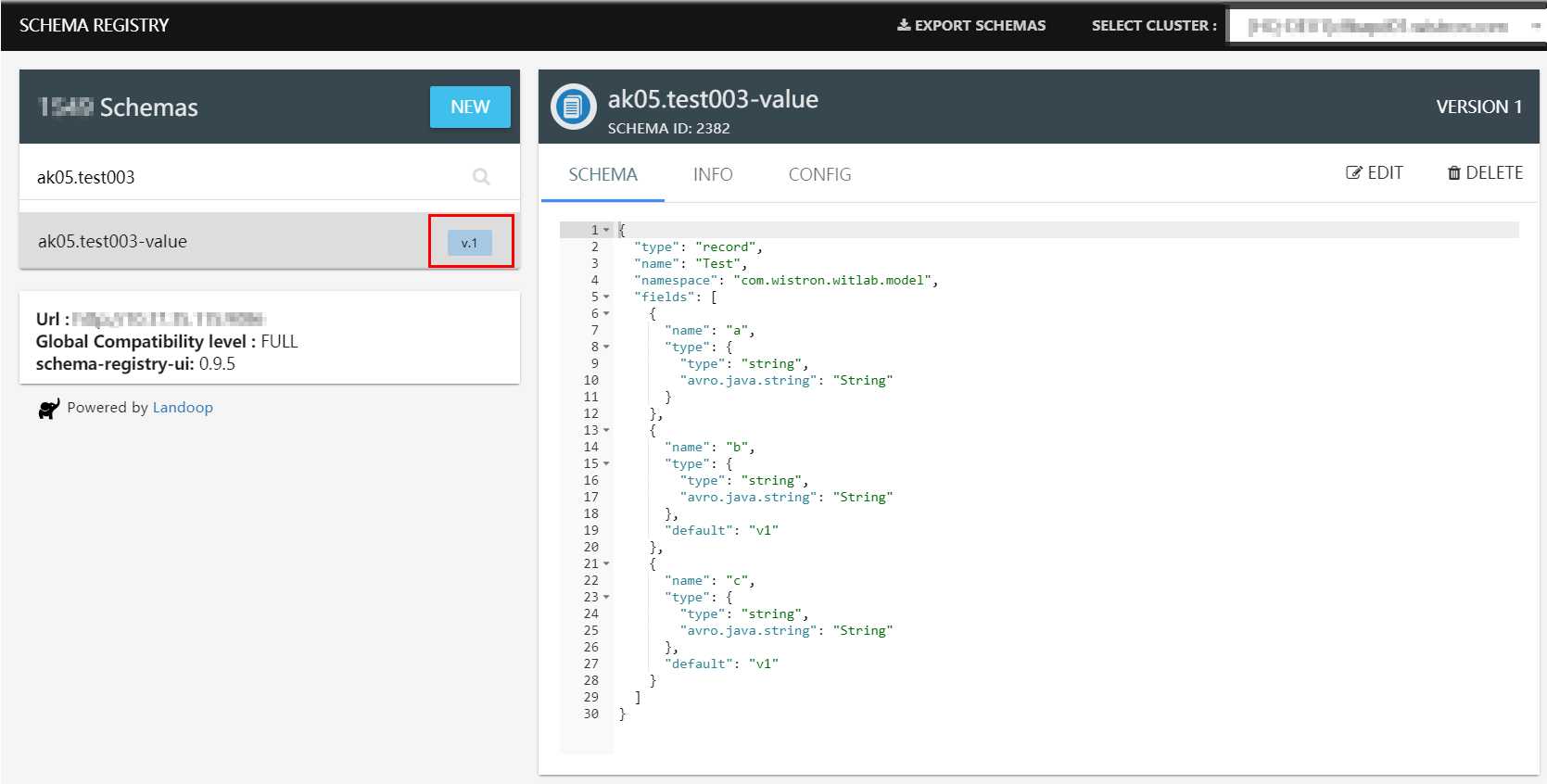
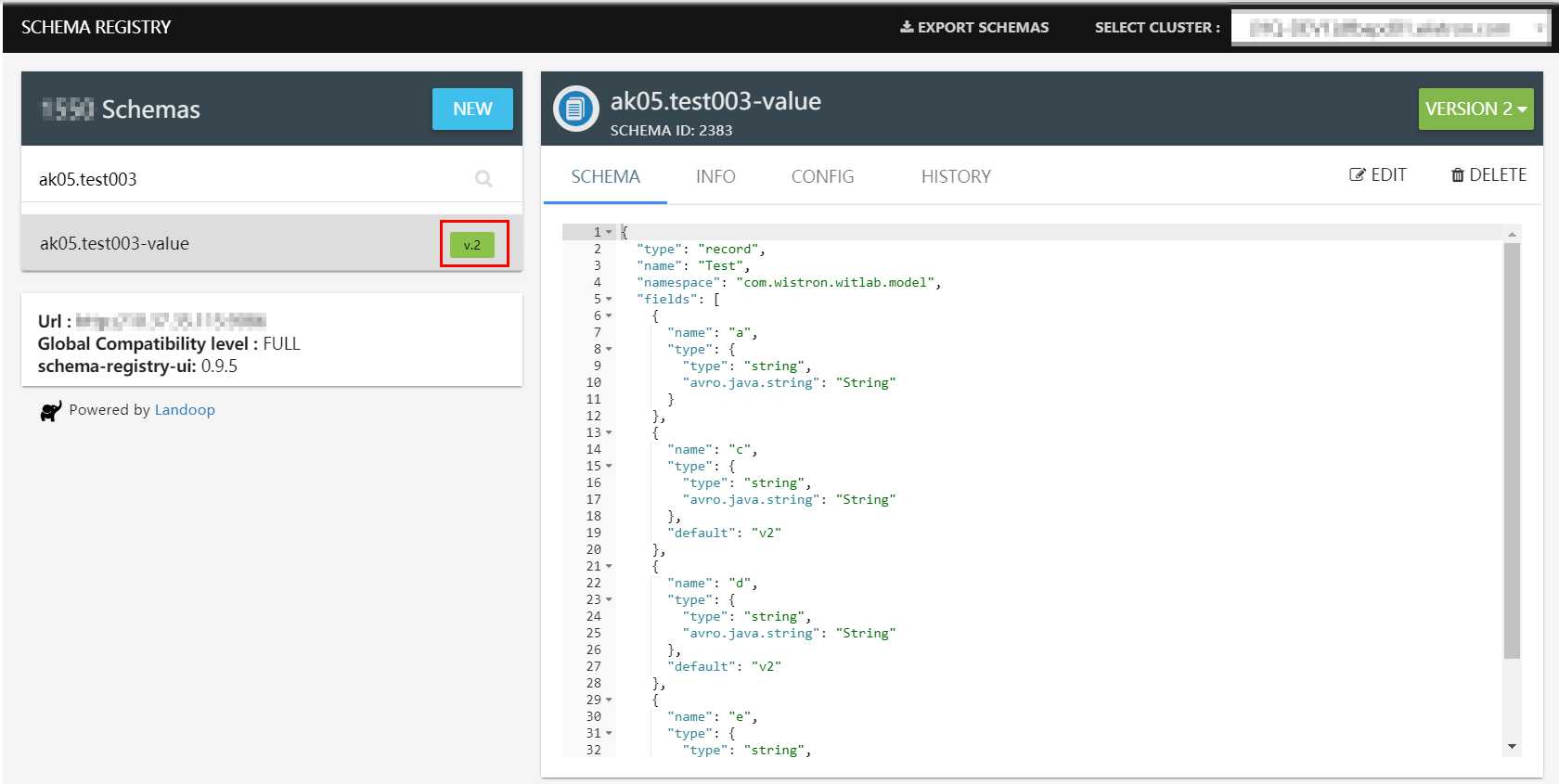
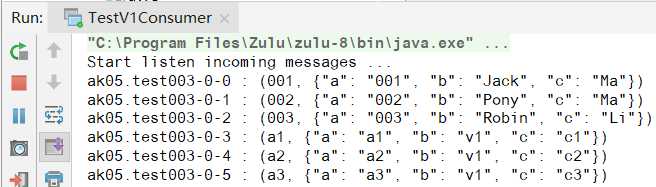
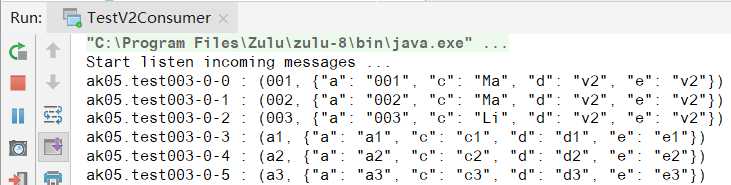
标签:enable com common plugins nap 图片 logical 信息 bsp 为了测试Avro Schema的兼容性,新建2个Java project,其中v1代表的是第一个版本, v2代表的是第二个版本。 2个project结构如下 v1的主要代码: pom.xml test.avsc TestV1Producer.java TestV1Consumer.java v2的主要代码: pom.xml与v1一致 test-v2.avsc TestV2Producer.java TestV2Consumer.java 测试步骤: 1. 去schema registry UI查看schema信息,此时schema版本是v.1 2. Run TestV2Producer,发送成功 去schema registry UI查看schema信息,此时schema版本是v.2 3. Run TestV1Consumer,用旧schema去读新数据,测试forward(向前兼容),可以看到,新旧资料都读取了 4. Run TestV2Consumer,用新schema去读旧数据,测试backward(向后兼容) 用Java来测试Avro数据格式在Kafka的传输,及测试Avro Schema的兼容性 标签:enable com common plugins nap 图片 logical 信息 bsp 原文地址:https://www.cnblogs.com/fangjb/p/13355086.html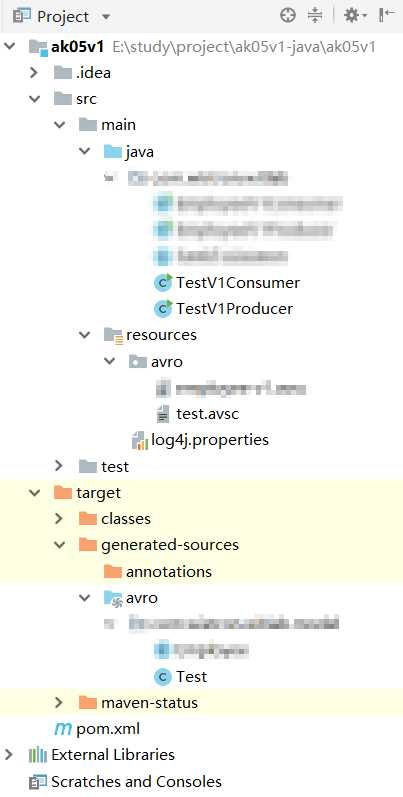


xml version="1.0" encoding="UTF-8"?>
project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
modelVersion>4.0.0modelVersion>
groupId>com.testgroupId>
artifactId>ak05v1artifactId>
version>1.0-SNAPSHOTversion>
properties>
avro.version>1.8.2avro.version>
kafka.version>1.1.0kafka.version>
confluent.version>5.3.0confluent.version>
properties>
repositories>
repository>
id>maven.repositoryid>
url>https://maven.repository.redhat.com/earlyaccess/all/url>
repository>
repositories>
dependencies>
dependency>
groupId>org.apache.avrogroupId>
artifactId>avroartifactId>
version>${avro.version}version>
dependency>
dependency>
groupId>org.apache.kafkagroupId>
artifactId>kafka-clientsartifactId>
version>${kafka.version}version>
dependency>
dependency>
groupId>io.confluentgroupId>
artifactId>kafka-avro-serializerartifactId>
version>${confluent.version}version>
dependency>
dependency>
groupId>org.slf4jgroupId>
artifactId>slf4j-apiartifactId>
version>1.7.25version>
dependency>
dependency>
groupId>org.slf4jgroupId>
artifactId>slf4j-log4j12artifactId>
version>1.7.25version>
dependency>
dependencies>
build>
plugins>
plugin>
groupId>org.apache.maven.pluginsgroupId>
artifactId>maven-compiler-pluginartifactId>
version>3.7.0version>
configuration>
source>1.8source>
target>1.8target>
configuration>
plugin>
plugin>
groupId>org.apache.avrogroupId>
artifactId>avro-maven-pluginartifactId>
version>${avro.version}version>
executions>
execution>
phase>generate-sourcesphase>
goals>
goal>schemagoal>
goal>protocolgoal>
goal>idl-protocolgoal>
goals>
configuration>
sourceDirectory>${project.basedir}/src/main/resources/avrosourceDirectory>
stringType>StringstringType>
createSetters>falsecreateSetters>
enableDecimalLogicalType>trueenableDecimalLogicalType>
fieldVisibility>privatefieldVisibility>
configuration>
execution>
executions>
plugin>
plugin>
groupId>org.codehaus.mojogroupId>
artifactId>build-helper-maven-pluginartifactId>
version>3.0.0version>
executions>
execution>
id>add-sourceid>
phase>generate-sourcesphase>
goals>
goal>add-sourcegoal>
goals>
configuration>
sources>
source>target/generated-sources/avrosource>
sources>
configuration>
execution>
executions>
plugin>
plugins>
build>
project>
{
"type": "record",
"namespace": "com.model",
"name": "Test",
"fields": [
{ "name": "a", "type": "string"},
{ "name": "b", "type": "string", "default":"v1"},
{ "name": "c", "type": "string", "default":"v1"}
]
}
package com.test;
import com.model.Test;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
/**
* 示範如何使用SchemaRegistry與KafkaAvroSerializer來傳送資料進Kafka
*/
public class TestV1Producer {
private static String KAFKA_BROKER_URL = "localhost:9092"; // Kafka集群在那裡?
//private static String SCHEMA_REGISTRY_URL = "http://10.37.35.115:9086"; // SchemaRegistry的服務在那裡?
private static String SCHEMA_REGISTRY_URL = "https://cp1.demo.playground.landoop.com/api/schema-registry";
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 步驟1. 設定要連線到Kafka集群的相關設定
Properties props = new Properties();
props.put("bootstrap.servers", KAFKA_BROKER_URL); // Kafka集群在那裡?
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定msgKey的序列化器
props.put("value.serializer", "io.confluent.kafka.serializers.KafkaAvroSerializer"); // -- 指定msgValue的序列化器
//props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("schema.registry.url", SCHEMA_REGISTRY_URL);// SchemaRegistry的服務在那裡?
props.put("acks","all");
props.put("max.in.flight.requests.per.connection","1");
props.put("retries",Integer.MAX_VALUE+"");
// 步驟2. 產生一個Kafka的Producer的實例 > producer = new KafkaProducer(props); // msgKey是string, msgValue是Employee
// 步驟3. 指定想要發佈訊息的topic名稱
String topicName = "ak05.test002";
try {
// 步驟4. 直接使用Maven從scheam產生出來的物件來做為資料的容器
// 送進第1個員工(schema v1)
Test test = Test.newBuilder()
.setA("001")
.setB("Jack")
.setC("Ma")
.build();
RecordMetadata metaData = producer.send(new ProducerRecordString, Test>(topicName, test.getA(), test)).get(); // msgKey是string, msgValue是Employee
System.out.println(metaData.offset() + " --> " + test);
// 送進第2個員工(schema v1)
test = Test.newBuilder()
.setA("002")
.setB("Pony")
.setC("Ma")
.build();
metaData = producer.send(new ProducerRecordString, Test>(topicName, test.getA(), test)).get(); // msgKey是string, msgValue是Employee
System.out.println(metaData.offset() + " --> " + test);
// 送進第3個員工(schema v1)
test = Test.newBuilder()
.setA("003")
.setB("Robin")
.setC("Li")
.build();
metaData = producer.send(new ProducerRecordString, Test>(topicName, test.getA(), test)).get(); // msgKey是string, msgValue是Employee
System.out.println(metaData.offset() + " --> " + test);
} catch(Exception e) {
e.printStackTrace();
} finally {
producer.flush();
producer.close();
}
}
}
package com.test;
import com.model.Test;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.record.TimestampType;
import java.util.Arrays;
import java.util.Properties;
/**
* 示範如何使用SchemaRegistry與KafkaAvroDeserializer來從Kafka裡讀取資料
*/
public class TestV1Consumer {
private static String KAFKA_BROKER_URL = "localhost:9092"; // Kafka集群在那裡?
private static String SCHEMA_REGISTRY_URL = "http://10.37.35.115:9086"; // SchemaRegistry的服務在那裡?
public static void main(String[] args) {
// 步驟1. 設定要連線到Kafka集群的相關設定
Properties props = new Properties();
props.put("bootstrap.servers", KAFKA_BROKER_URL); // Kafka集群在那裡?
props.put("group.id", "ak05-v1"); //
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // 指定msgKey的反序列化器
props.put("value.deserializer", "io.confluent.kafka.serializers.KafkaAvroDeserializer"); // 指定msgValue的反序列化器
props.put("schema.registry.url", SCHEMA_REGISTRY_URL); //
props.put("specific.avro.reader", "true"); // // (如果沒有設定, 則都會以GenericRecord方法反序列)
props.put("auto.offset.reset", "earliest"); // 是否從這個ConsumerGroup尚未讀取的partition/offset開始讀
props.put("enable.auto.commit", "false");
// 步驟2. 產生一個Kafka的Consumer的實例
Consumer
{
"type": "record",
"namespace": "com.wistron.witlab.model",
"name": "Test",
"fields": [
{ "name": "a", "type": "string"},
{ "name": "c", "type": "string", "default": "v2"},
{ "name": "d", "type": "string", "default": "v2"},
{ "name": "e", "type": "string", "default": "v2"}
]
}
package com.test;
import com.model.Test;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
/**
* 示範如何使用SchemaRegistry與KafkaAvroSerializer來傳送資料進Kafka
*/
public class TestV2Producer {
private static String KAFKA_BROKER_URL = "localhost:9092"; // Kafka集群在那裡?
//private static String SCHEMA_REGISTRY_URL = "http://10.37.35.115:9086"; // SchemaRegistry的服務在那裡?
private static String SCHEMA_REGISTRY_URL = "https://cp1.demo.playground.landoop.com/api/schema-registry";
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 步驟1. 設定要連線到Kafka集群的相關設定
Properties props = new Properties();
props.put("bootstrap.servers", KAFKA_BROKER_URL); // Kafka集群在那裡?
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定msgKey的序列化器
props.put("value.serializer", "io.confluent.kafka.serializers.KafkaAvroSerializer"); // //props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("schema.registry.url", SCHEMA_REGISTRY_URL);// SchemaRegistry的服務在那裡?
props.put("acks","all");
props.put("max.in.flight.requests.per.connection","1");
props.put("retries",Integer.MAX_VALUE+"");
// 步驟2. 產生一個Kafka的Producer的實例
Producer
package com.test;
import com.model.Test;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.record.TimestampType;
import java.util.Arrays;
import java.util.Properties;
/**
* 示範如何使用SchemaRegistry與KafkaAvroDeserializer來從Kafka裡讀取資料
*/
public class TestV2Consumer {
private static String KAFKA_BROKER_URL = "localhost:9092"; // Kafka集群在那裡?
private static String SCHEMA_REGISTRY_URL = "http://10.37.35.115:9086"; // SchemaRegistry的服務在那裡?
public static void main(String[] args) {
// 步驟1. 設定要連線到Kafka集群的相關設定
Properties props = new Properties();
props.put("bootstrap.servers", KAFKA_BROKER_URL); // Kafka集群在那裡?
props.put("group.id", "ak05-v2"); //
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // 指定msgKey的反序列化器
props.put("value.deserializer", "io.confluent.kafka.serializers.KafkaAvroDeserializer"); // 指定msgValue的反序列化器
props.put("schema.registry.url", SCHEMA_REGISTRY_URL); //
props.put("specific.avro.reader", "true"); // // (如果沒有設定, 則都會以GenericRecord方法反序列)
props.put("auto.offset.reset", "earliest"); // 是否從這個ConsumerGroup尚未讀取的partition/offset開始讀
props.put("enable.auto.commit", "false");
// 步驟2. 產生一個Kafka的Consumer的實例
Consumer
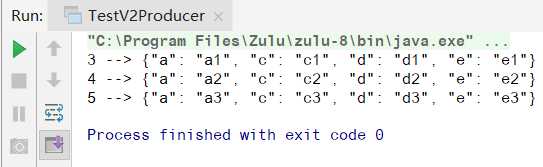
Run TestV1Producer,发送成功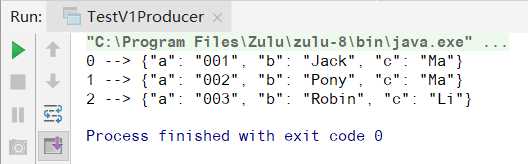
下一篇:Java设计模式6大原则
文章标题:用Java来测试Avro数据格式在Kafka的传输,及测试Avro Schema的兼容性
文章链接:http://soscw.com/essay/74662.html