12个行业月均阅读超100亿,看Spark如何助力微博Feed算法提升活跃度
2021-03-18 06:25
标签:关系 超过 正文 相关 样本 联网 hive 项目 spark 编者按:本文由高可用架构向黄波约稿,介绍黄波在 Spark Summit China 2016 中的演讲精华,并侧重对微博系统和 Feed 系统进行了更多的介绍。 新浪微博是中国领先的社交媒体平台,是一个基于用户关系来分享、传播以及获取中文内容的平台。用户可以通过 Web、移动等各种客户端,以文字、图片、视频等形式更新信息,同时实现即时分享。 根据微博 2016 年第一季度财报数据,截止一季度末,微博月活跃用户达到 2.61 亿,日活跃用户达到 1.2 亿。在微博垂直运营的行业中,已经有 12 个行业的月均阅读量超过 100 亿。微博将与很多专业机构在内容生产,账号成长,收入变现等多个方面展开合作,在不同垂直领域构建行业生态。 巨大的用户规模和业务访问量,需要强大技术系统支撑,下面将介绍微博的技术架构。微博技术架构最基本的设计思想是分层,这是大中型互联网系统的常见设计思路。 业务层主要直接面对用户,为用户提供产品功能,满足用户需求。这里的用户包括微博产品大众用户、商业产品企业用户、第三方应用开发者等。微博为大众用户提供了 Web、移动客户端等产品,为企业用户提供了粉丝通等商业产品,为第三方开发者提供开放平台等产品,动态平台、广告服务平台、开发平台等系统分别提供相应的技术支持。 平台层主要提供微博内部公共功能接口以及承载微博业务流量。平台层主要有接口、缓存、存储、队列和队列处理等模块。 接口模块主要实现与 Web 页面、移动客户端的接口交互,定义统一的接口规范,其中 Feed 服务是最核心的接口服务之一。 缓存模块通过统一的分布式缓存和分级缓存服务,提高系统性能,承载绝大多数业务流量,目前微博主要使用 Redis 和 Memcached 等作为缓存。 存储模块主要用于存储业务数据,包括千亿级的微博内容和用户关系数据,目前微博内容主要使用 MySQL、Redis 和 HBase 等存储系统。 队列模块和队列处理模块是异步化的关键。以发布微博为例,发博是一个非常复杂、耗时的操作,它要写入数据库、统计索引、内容分析、传入后台。如果我们要把所有的步骤都做完,用户需要在前端等待很长的时间;如果某一个环节失败,即使已经成功写入数据库,用户将得到“发布失败”的提示,这样的用户体验非常糟糕。 异步化之后,发布微博成为一个异步操作,发布成功我们就提示成功,同时将微博写入到 MemcacheQ 等消息队列中;队列处理模块在后台循环消费消息队列,进行写入数据库、内容分析等复杂、耗时操作。 异步化能显著减少写操作接口响应时间,减少用户等待时间,改善写操作用户体验;同时,由于复杂操作转化为后台处理,提高了接口并发处理能力,极大提高了整个系统吞吐量。 大数据层主要提供基础的数据服务和算法服务。 存储模块包括存储系统和队列系统。存储系统包括存储离线数据的 HDFS 分布式文件系统、存储在线数据的 Redis 和 HBase 等 NoSQL 系统、以及存储在线数据的关系数据库 MySQL 系统。队列系统包括微博自主研发 Firehose 队列,开源的 Scribe 和 Kafka 队列。队列系统用于实时接收事件和数据。 计算模块包括计算系统和算法系统。计算系统包括处理离线数据的分布式计算系统、处理队列实时数据的实时流计算系统。算法系统包括模型训练机器学习系统,以及实时、离线生成各类特征的特征工程系统。 服务模块包括数据服务和算法服务系统,提供用户画像、标签服务、推荐引擎等数据服务,提供文本处理、图片处理、分类预测等算法服务。 应用模块主要承担数据、算法和产品策略的结合。大部分的基础数据和算法已经基本可用,但是由于产品场景的不同,数据、算法需要和产品策略进行针对性的融合和优化,最大限度提高最终产品效果。 业务层、平台层、大数据层相互依赖,结合在一起形成完整的技术生态系统。 当你发布一条微博,关注你的粉丝会在一定的时间内收到你的微博。你的粉丝不仅仅会关注你,还会关注其他朋友、明星、网红、企业、政府等。当他在 Web 或者移动客户端进行阅读消费时,若干微博依次展现形成了信息流,我们称之为 Feed。 ?Feed 的基本流程是:当你发布一篇微博,会将该微博作为物料进行存储;当你的粉丝进行 Feed 阅读消费时,会将他的关注人的微博进行筛选和聚合,并进行组合排序,最终展现到你的粉丝面前。流程如下图所示。 推模式就是,用户 A 关注了用户 B,用户 B 每发布一个微博,后台遍历用户 B 的粉丝,往他的粉丝的 Feed 里面插入一条物料。与推模式相反,拉模式则是,用户每次刷新 Feed 时,都去遍历关注的人,把关注人最新的微博物料拉取回来。由于微博是以单向关注为主的社区,关注和粉丝非常不对等。亿级的粉丝数对推模式的时效性、有效性等方面形成很大挑战,因此,微博采取拉模式为主进行 Feed 的聚合,在某些特殊场景下才使用推模式进行补充。 在算法方面,内容质量模型、排序模型、防抓站模型等都和 Spark MLlib 进行了结合;在物料方面,动态物料生成等方面有使用 Spark Streaming;在特征方面,Spark Streaming 用于生成实时特征,Spark 和 Spark GraphX 等用于生成用户特征、关系特征等离线特征。 在 Feed 场景下,物料问题是我们遇到的第一个问题,物料方面包括数量和质量的问题。我们通过引入关系物料、非关系物料、个性化兴趣物料来解决数量问题,通过引入用户质量模型、内容质量模型类解决质量问题。排序问题是最重要的问题之一,其中主要是排序优化的问题,我们通过引入样本、模型、特征等来解决,下一节将会进行详细介绍。 Feed 本质是上物料的分发,就是说当用户消费 Feed 时,系统需要把跟用户有关的或者用户感兴趣的事情告诉他。我们在优化 Feed 时,发现了如下问题: 我们的解决思路和方案是: 用户阅读 Feed 中的微博内容,我们称之为曝光;微博在 Feed 中展示时,有若干区域可以供用户进行点击和互动,如下图中的红色区域。互动包括转发、评论、赞等强互动,阅读、点击正文页、点击作者、点击长文、点击图片等弱互动,以及“不感兴趣”等负反馈互动。 定义正负样本之后,我们需要进行样本数据的收集,包括实时样本收集和离线样本收集。 Spark Streaming 和 Storm 等实时流处理系统会实时获取曝光和互动数据,并联合形成相应的正负样本,在线的正负样本同时会实时地同步到离线 Hadoop 系统中。系统流程如下图所示。 ? 我们通过引入排序模型来优化排序,主要工作有模型训练和模型预测。 在模型训练方面,由于我们每天有千亿级的曝光,样本数据多,特征维度多;因此我们采用工业上通用的逻辑回归模型(Logistic Regression,LR),并使用 Spark MLlib 进行离线训练。 逻辑回归模型足够简单,速度较快,但是学习能力有限;我们引入 GBDT(Gradient Boosting Decision Tree)和逻辑回归模型进行融合。 在模型预测方面,为了和线上系统整合,我们开发了模型 RPC 服务(ModelService),如下图所示。 为了保证服务的高可用性和高可扩展性,我们将模型服务设计成无状态的完整独立服务。经过负载均衡模型进行模型服务的健康状态监测,如果某个模型服务出现问题,将被摘除,不再对外提供服务。同时,负载均衡模型还提供流量分发功能。由于每个模型服务都是完整和独立的,我们进行系统扩展和服务扩容非常方便。 我们引入 Hadoop 和 Spark 等分布式系统来解????????????????????决离线特征的解决数据量问题和计算量问题,通过引入 Hive/Spark SQL 解决离线特征的开发效率问题。我们引入 Storm 和 Spark Streaming 等实时流计算系统进行实时计算,开发流式语言 WeiPig 解决开发效率问题。 (点击图片可全屏缩放) WeiPig 基本解析流程是通过语法解析,形成语法抽象树;通过遍历 AST,生成执行逻辑;通过反射生成可以在 Storm 或 Spark Streaming 中可执行的原语和代码。通过将生成的 Storm 和 Spark Streaming 作业提交到集群中进行真正的实时流处理。 在 Storm 和 Spark Streaming 选项方面。Storm 使用流水式并行计算方式,数据流入到计算节点进行计算,移动数据而不是移动计算;Spark Streaming 使用数据批处理方式,切分数据形成任务进行计算,移动计算而不移动数据。Storm基本是若干毫秒的延迟,Spark Streaming 一般是若干秒的延迟。对于要求毫秒级延迟或者处理过程相对简单的应用,我们一般选用 Storm;对于秒级或分钟级延迟或者处理过程包含聚合等复杂运算的应用,我们一般选用 Spark Streaming。 总结下特征方面的流程: Spark Streaming 和 Storm 等实时流处理系统会实时获取发博、曝光和互动数据,抽取相应的特征,形成实时特征。实时特征同步到离线 Hadoop 系统之后,经过 Spark、Hive、Hadoop 等分布式计算,生成新的离线特征。离线特征定期加载到在线特征库中,和实时特征进行融合,最终形成统一的在线特征库。系统流程如下图所示。 样本、模型、特征等是 Feed 排序三要素,样本用于量化用户体验,模型用于优化排序和用户体验,特征用于区分微博质量和用户个性化需求。样本和特征结合到一起进行离线训练,得到排序模型;模型和特征结合到一起进行在线预测,最终用于 Feed 的排序。 样本、模型、特征等整合起来的系统流程如下图所示。 6期高可用架构精华,年薪过百万程序员都看过,全都免费下载了 (点击图片) 为什么顶尖的技术大咖都赶往怀柔,参加高可用架构社区郊游活动 本文是业界第一次深入介绍 Spark 如何用在微博 Feed 排序的场景,对本文话题感兴趣或有疑问,欢迎直接在文章后留言,作者会直接对提问进行答疑。 转载请注明来自高可用架构「ArchNotes」微信公众号及包含以下二维码。 12个行业月均阅读超100亿,看Spark如何助力微博Feed算法提升活跃度 标签:关系 超过 正文 相关 样本 联网 hive 项目 spark 原文地址:https://blog.51cto.com/14977574/2547708 黄波,2010 年加入新浪微博,微博研发中心 Feed 技术专家,负责微博 Feed 流排序和推荐相关项目。目前专注于基于 Spark、Storm 等计算平台的大数据处理,致力于将分布式计算与机器学习技术应用于微博 Feed 排序和推荐等场景。曾供职于百度,参与开发分布式文件系统。个人擅长分布式系统、实时流系统、Feed 系统、数据挖掘、大数据平台等相关领域。
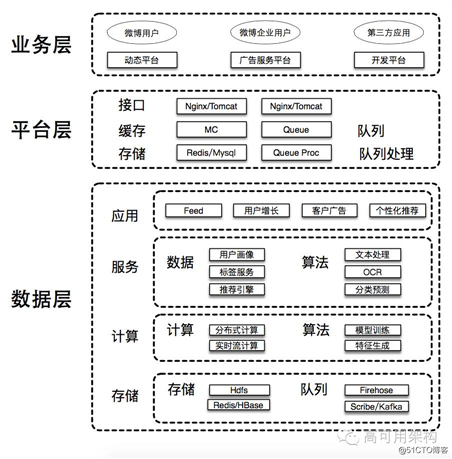
黄波,2010 年加入新浪微博,微博研发中心 Feed 技术专家,负责微博 Feed 流排序和推荐相关项目。目前专注于基于 Spark、Storm 等计算平台的大数据处理,致力于将分布式计算与机器学习技术应用于微博 Feed 排序和推荐等场景。曾供职于百度,参与开发分布式文件系统。个人擅长分布式系统、实时流系统、Feed 系统、数据挖掘、大数据平台等相关领域。一、新浪微博及其三层技术架构
微博的技术?架构基本上分为三层:业务层、平台层、大数据层。
二、微博的 Feed 场景

1. 推模式和拉模式
Feed 在技术上,有推模式和拉模式两种实现。
2. 和 Spark 结合
3. 遇到的问题
三、微博的 Feed 排序场景
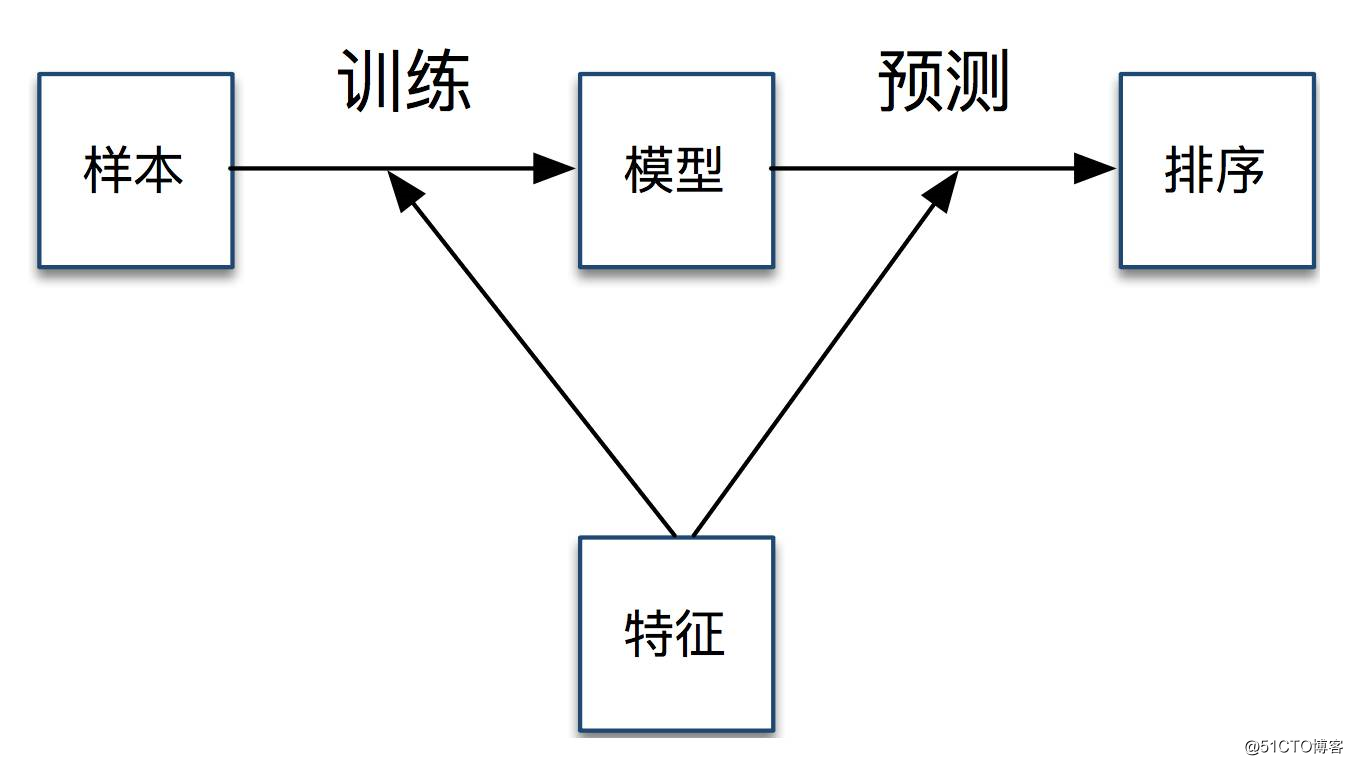
排序的三大要素:样本、模型、特征。样本和特征结合到一起进行????离线训练,得到排序模型;模型和特征结合到一起进行在线预测,最终用于 Feed 的排序。
?1. 样本
我们通过引入样本来量化用户体验。
通过是否互动来定义正负样本,在曝光一定时间内接收到相应互动,我们称之为正样本,否则为负样本。
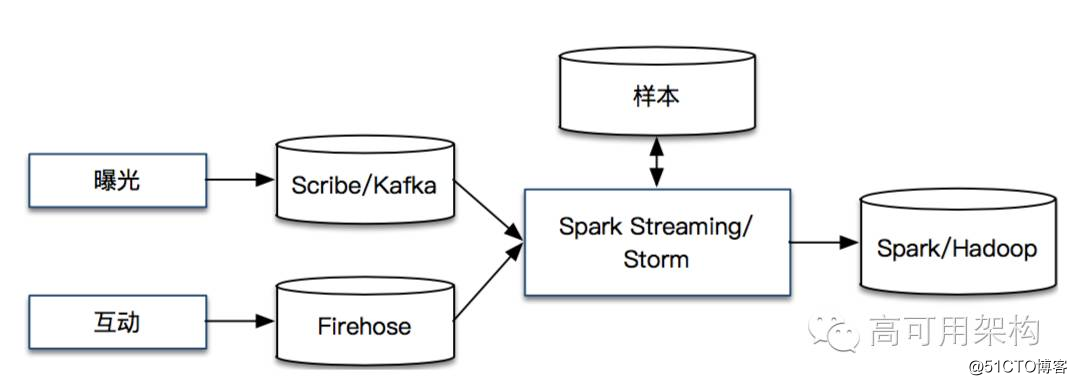
2. 模型
??
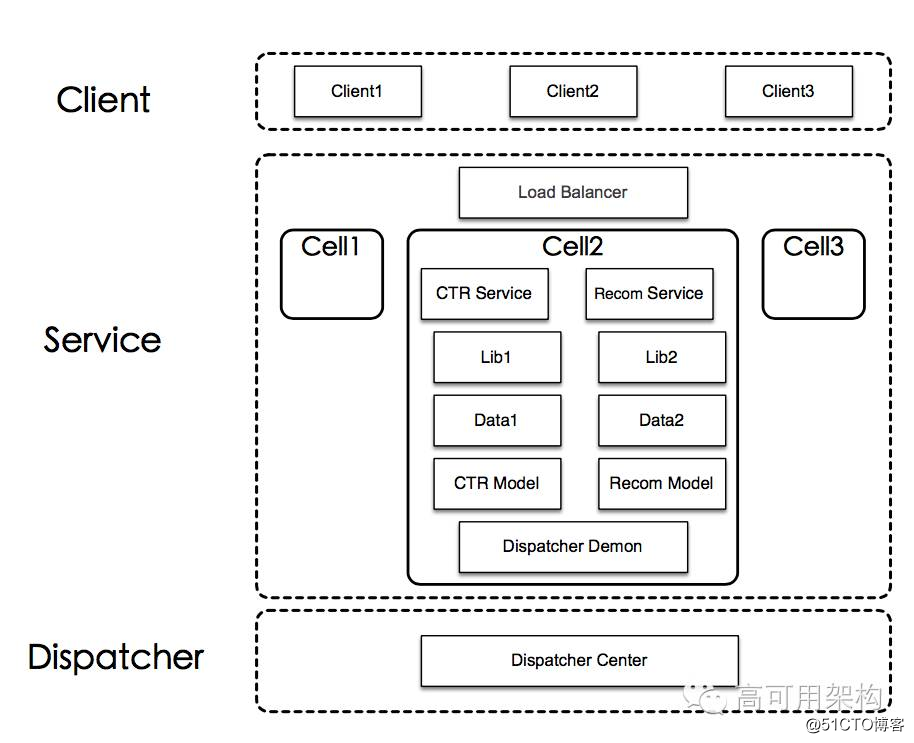
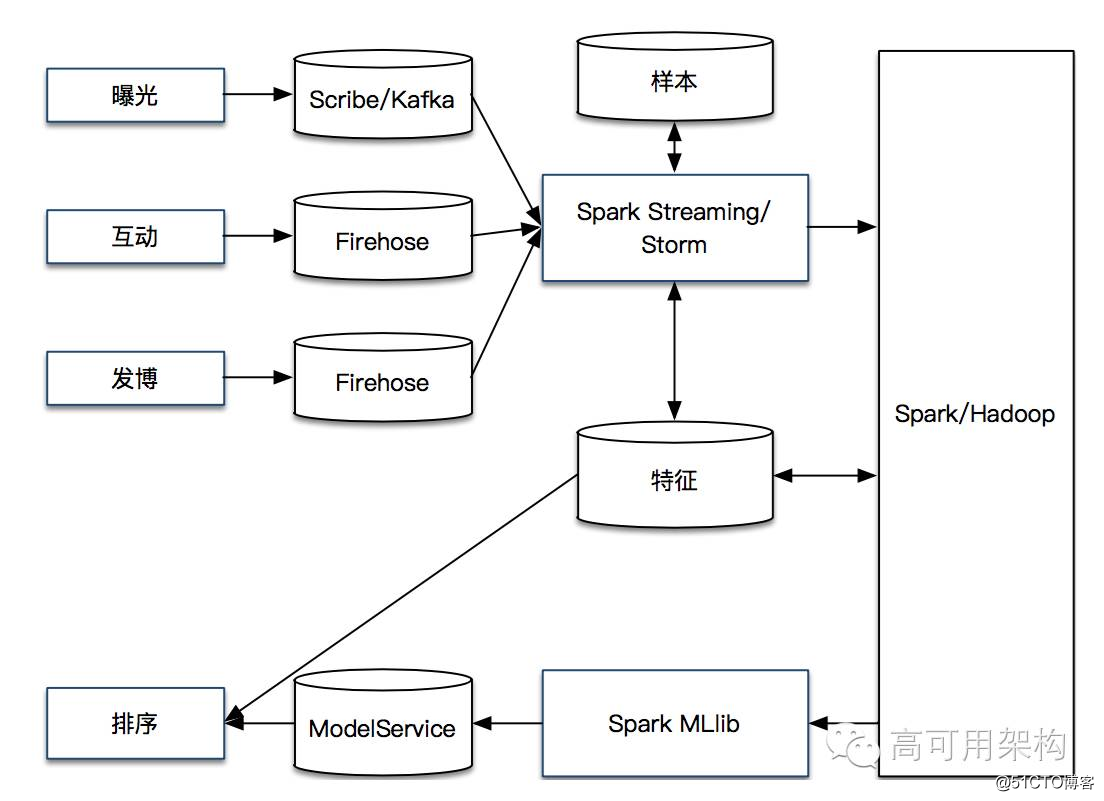
??总结下模型方面的流程,样本通过 Spark MLlib 进行离线训练;经过评估,将稳定的模型通过到线上的模型服务(ModelService)中;模型服务(ModelService)和在线特征结合起来,对 Feed 排序进行在线预测。系统流程如下图所示。
3. 特征
我们引入特征来区分微博质量和用户个性化需求。
?
?内部开发的流式语言 WeiPig 提供了 Pig on Storm 和 Pig on Spark Streaming 的功能。语法和 Pig 语法很类似,提供了若干原语,包括定义流式拓扑结构的 topology,定义数据输入的 input,定义数据处理的 task,定义数据输出的 output。同时还支持自定义 udf 函数等功能。语法示意如图所示。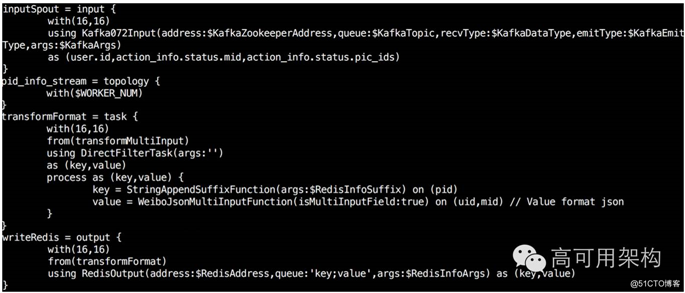
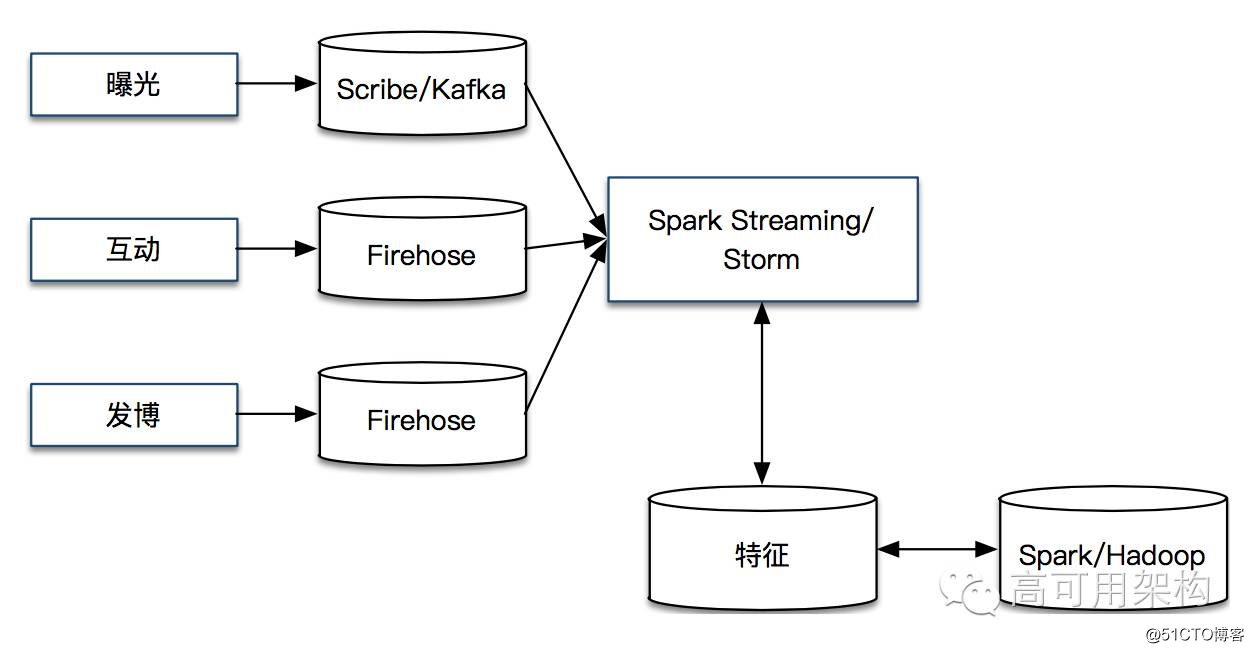
四、总结
参考阅读
高可用架构的读者他们也在看
高可用架构
改变互联网的构建方式

长按二维码 关注「高可用架构」公众号
下一篇:C++在C的基础上改进了哪些细节
文章标题:12个行业月均阅读超100亿,看Spark如何助力微博Feed算法提升活跃度
文章链接:http://soscw.com/index.php/essay/65657.html